Toda esta aventura comienza con un archivo llamado pretty_raw, sin extensión. Porque sí. Porque las extensiones son una invención heredada de CP/M, precursor de MS-DOS, que Windows terminó de popularizar. Porque son innecesarias. Y porque echo de menos cuando los archivos se reconocían por sus permisos… y no por cómo se llamaban.
Como iba diciendo, todo esto comienza mediante el análisis de pretty_raw. Mirando debajo de la falda con un editor hexadecimal encontramos unos cuantos bytes aleatorios hasta dar con una cabecera PNG.
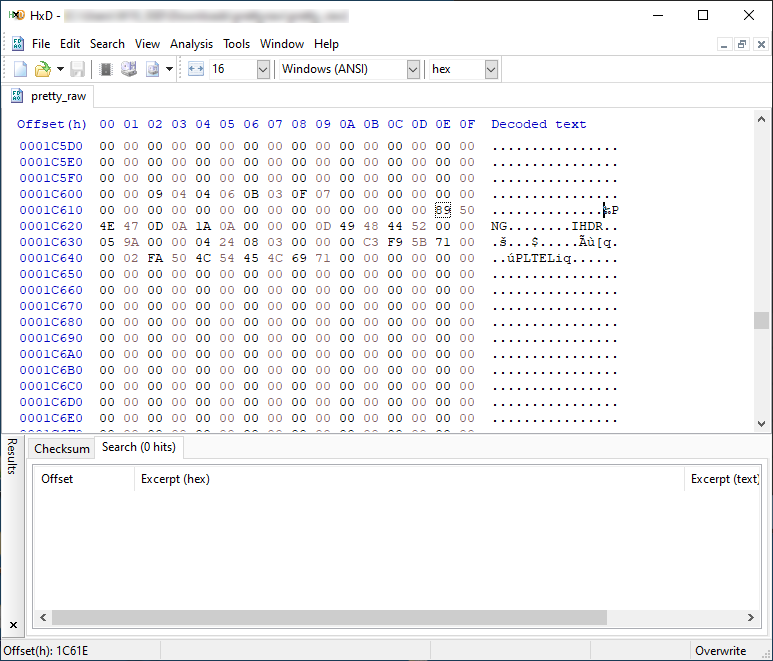
Si atendemos a la captura, justo antes de la cabecera PNG tenemos 116.254 bytes (0x1C61E). Tomad nota que este número será relevante más adelante.
Extraemos el PNG, lo visualizamos y lo pasamos por todas las herramientas habidas y por haber. Nada funciona. Volvemos a visualizarlo con atención y vemos que hace referencia a un archivo llamado flag.png con unas dimensiones que no coinciden con la extraída.
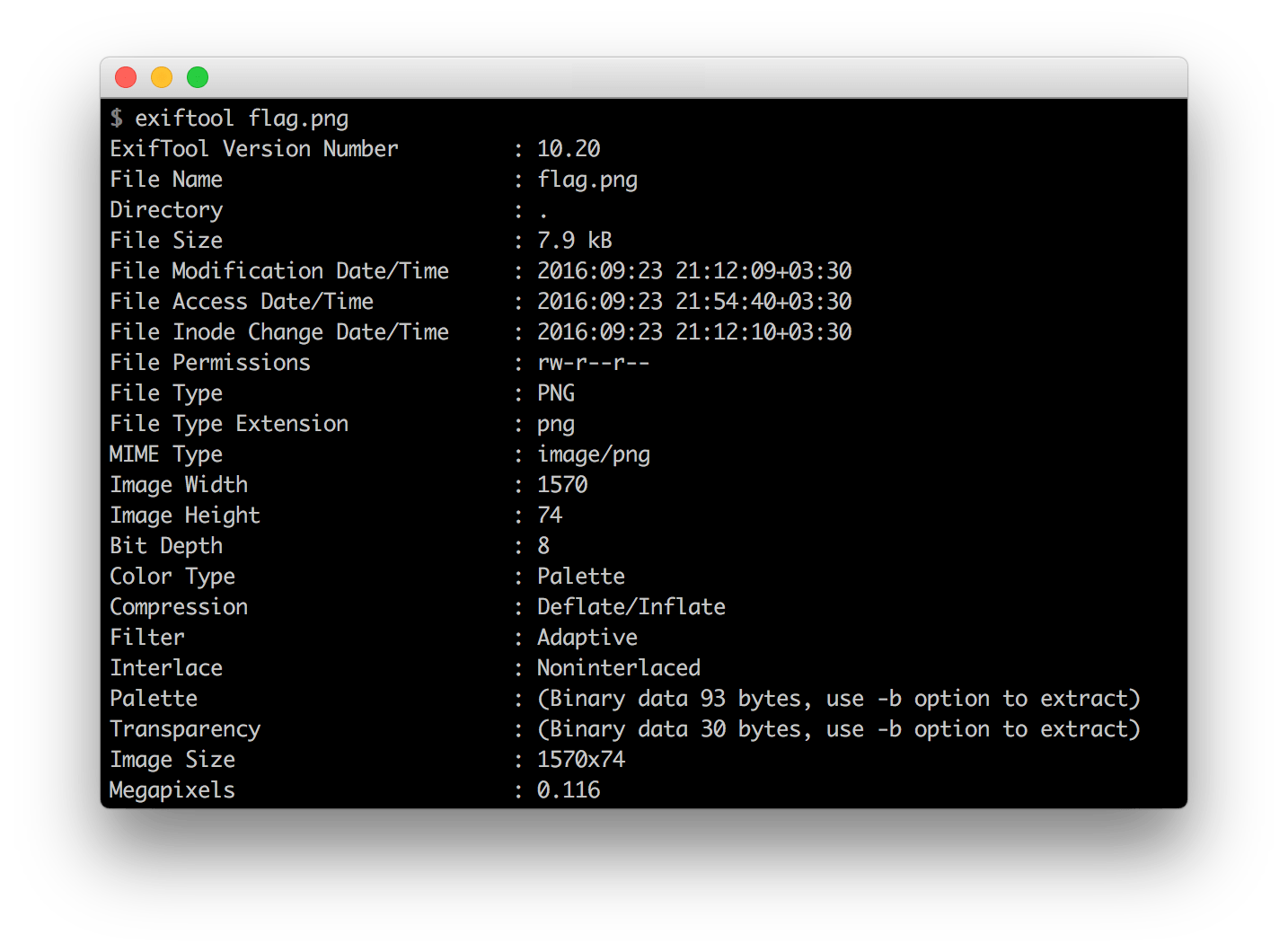
Toca centrarse y pensar en que camino tomar. Hemos gastado tiempo con el PNG extraído y quizá lo mejor sea centrarse en los bytes que inicialmente hemos descartado. En concreto se trata de un bloque de 116.254 bytes, pero espera, 1570×74=116.180 bytes. ¡Mierda!, no coincide exactamente con los bytes extraídos. Bueno, da igual. Si suponemos que el PNG que buscamos no tiene compresión y que cada pixel ocupa un byte (escala de grises y 8 bits), su tamaño depende únicamente de la geometría y de cómo se almacenan las filas en memoria. Vamos a procesarlo con Python para salir de dudas.
import numpy as np
from PIL import Image
INPUT_FILE = "pretty_raw"
OUTPUT_FILE = "pretty_raw_flag.png"
WIDTH = 1570 # ¿estás seguro?
HEIGHT = 74
DEPTH = 8 # bits
# Leer archivo como RAW
with open(INPUT_FILE, "rb") as f:
raw = f.read()
expected_size = WIDTH * HEIGHT
if len(raw) < expected_size:
raise ValueError("El archivo no tiene suficientes datos")
# Convertir a array numpy (grayscale 8 bits)
img = np.frombuffer(raw[:expected_size], dtype=np.uint8)
img = img.reshape((HEIGHT, WIDTH))
# Crear imagen
image = Image.fromarray(img, mode="L")
image.save(OUTPUT_FILE)
print(f"Imagen generada correctamente: {OUTPUT_FILE}")
El script nos devuelve un PNG válido pero con las letras torcidas. Tras darle vueltas me di cuenta de que si en el script usamos como WIDTH=1571 en lugar de 1570, la imagen resultante es correcta y tiene todo el sentido del mundo ya que 1571×74=116.254, que son exactamente los bytes que se encuentran antes del png señuelo.

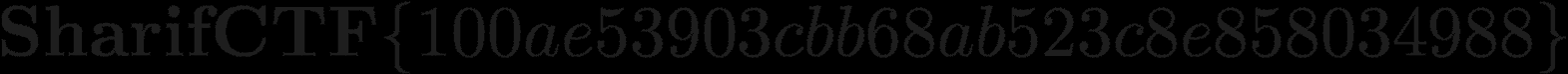
Aunque el ancho visible de la imagen es de 1570 píxeles, cada fila ocupa realmente 1571 bytes. Ese byte adicional actúa como relleno (padding) y forma parte del stride o bytes por fila. Ignorar este detalle lleva a un desplazamiento erróneo acumulativo y por eso se ve la imagen torcida. En este caso concreto da igual ya que el texto se aprecia, pero si el reto hubiera sido más exigente no se vería nada.